BERT 논문 정리
BERT
Bidirectional Encoder Representational from Transformers
초록
pre-trained 된 BERT 모델에 output 레이어만 추가하면 쉽게 파인튜닝이 가능하다. BERT는 개념적으로 간단하고 성능이 강력하다.
개요
Language model pre-training은 자연어 처리에 효율적인 성능을 보여주고 있다.
프리트레이닝된 언어표현을 적용하는 방법은 2가지가 있다.
- feature-based ex) ELMO(먼저 임베딩을 학습한 뒤 관련된 task를 붙여서 학습)
- fine-tuning ex) OpenAI GPT(transformer 사용 task와 관련된 것을 최소로 하여 간단하게 fine-tuning)
기존에는 두 방법에서 모두 단방향 모델을 사용하여 제한적임 (ELMO는 양방향을 사용하고 있지만 진정한 의미의 양방향이 아님)
그래서 BERT에서는 MLM(Masked Language Model)을 사용하여 양방향 구조를 도입
뒤의 내용
- 양방향이 왜 중요한지 설명
- pre-trained된 표현으로 task에 밀접한 엔지니어링 요소를 줄여줬다는 것을 보여줌
- SOTA(state-of-the-art)를 갈아치웠다는 것을 보여줌
관련연구
Feature-based
ELMO: 오른쪽 방향 LSTM + 왼쪽 방향 LSTM
(LSTM을 합치는 거라 진정한 의미의 양방향이 아니라고 함)
Fine-tuning
LM(language model)이 최신 트렌드
OpenAI GPT: 오른쪽 방향 transformer(transformer decoder)
비교
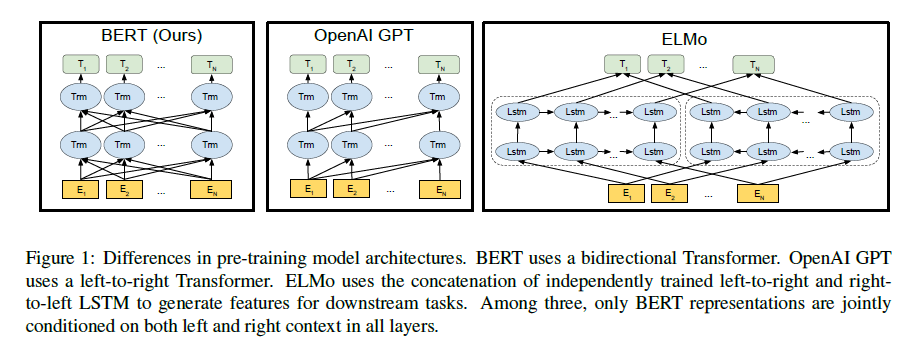
BERT: 양방향 transformer(transformer encoder)
BERT
모델 구조
BERT 모델 구조는 multi-layer 양방향 trasnformer encoder로 구성
L = 층의 개수(trasformer blocks)
H = hidden size
A = self-attention head의 개수
항상, feed-forward/filter size 는 H의 4배
BERT_BASE: L=12, H=768, A=12, 전체 파라미터 수 = 110M (OpenAI GPT와 동일하게 설정하여 비교)
BERT_LARGE = L=24, H=1024, A=16, 전체 파라미터 수 = 340M
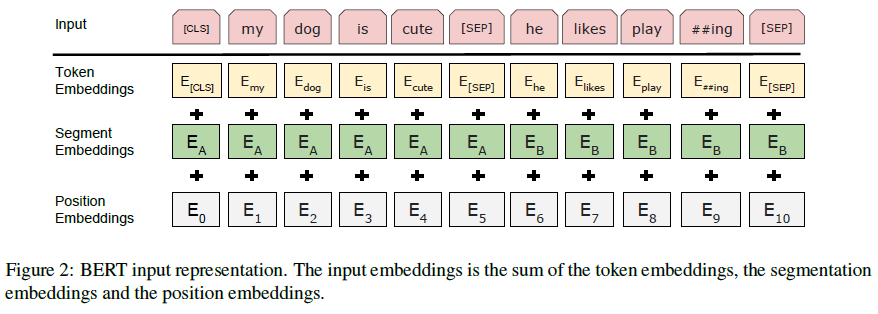
Input Representation
하나의 token sequence에서 여러 개의 문장이나 하나의 단어에 상관없이 표현 가능
Token Embedding, Segment Embedding, Position Embedding 3가지로 구성
- WordPiece embedding 사용(30000 토큰), ##으로 분리된 word piece 표시
- 512 token까지만 사용 가능 (그 이상은 OOM??)
- classification 문제인 경우 첫 번째 token embedding은 [CLS]
- 2개의 문장이 한 번에 들어 갈 수 있다.(실제 문장 단위가 아니어도 됨) 그래서 [SEP]를 사용하여 구분하고, A와 B로 표시하여 구분
- 단일 문장에서는 A만 사용
- positional embedding은 transformer에 나오는 내용
- segment embedding: A와 B로 문장 구분
Pre-training(Masked LM)
deep bidirectional representation을 위해 입력 토큰의 일부 비율을 랜덤으로 설정하고, 랜덤 토큰에 대해서만 predict
각 sequence에서 wordpiece 토큰 중 임의의 15%만 마스킹
위와 같은 방식으로 진행하면 양뱡향 pre-training이 가능하지만 2가지 단점이 존재
- pre-training과 fine-tunning이 맞지 않음 그래서 전체를 [MASK]로 바꾸지 않음
- 80%는 [MASK]로 교체(ex. my dog is hairy -> my dog is [MASK])
- 10%는 임의의 단어로 교체(ex. my dog is hairy -> my dog is apple)
- 10%는 그대로 유지(ex. my dog is hairy -> my dog is hairy)
transformer encoder는 어떤 단어가 교체되었고, 어떤 단어를 예측해야 하는 지 모르기 때문에 distributional contextual representation을 유지 가능 임의의 교체는 1.5%(15%의 10%)이므로, 모델이 언어를 이해하는 데 나쁜 영향을 주지 않음
- 각 배치에서 15%의 토큰만 예측에 사용하기 때문에 pre-training 단계가 많이 필요하다.
Pre-training(Next Sentence Prediction)
문장 A와 B가 있을 때, 50%는 A의 뒤에 B를 사용하고, 50% A의 뒤에 임의의 문장을 사용
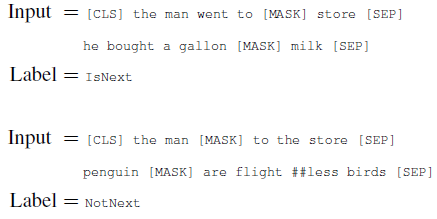
최종 pre-train model에서 97%~98% 정확도를 보인다.
Pre-training 과정
데이터: BooksCorpus(800M words) + English Wikipedia(2500M words)
sample 당 token 개수 <= 512
batch: 256 sequences( 256 sequences * 512 tokens = 128000 tokens/batch) for 1000000 step
대략 40 epoch (3.3 billon = 3,300,000,000)
Adam 사용(lr = 1e-4)
dropout은 모든 층에서 0.1
GELU 사용
LOSS = MLM의 평균 + NSP의 평균
BERT_BASE는 4TPU(16 TPU chips)로 4일동안 학습
BERT_LARGE는 16TPU(64 TPU chips)로 4일동안 학습
Fine-tuning 과정
분류 문제에서 새롭게 추가되는 파라미터는 K(분류되는 클래스의 수) x H(hidden size) ??
K x H 만큼 fully connected
fine-tuning 시 하이퍼파라미터는 batchsize, lr(adam), epoch 수를 빼고 유지하는 것이 좋다.
권장 값
| GPT | BERT | |
|---|---|---|
| 데이터 | BooksCorpus(800M) | BooksCorpus(800M) + WikiPedia(2500M) |
| [SEP]와 [CLS] 사용 | fine-tuning에서만 사용 | pre-training과 fine-tuning 모두 사용 |
| 학습 단위 | 1M steps(batch 32000 words) | 1M steps(128000 words) |
| learnging rate | 5e-5로 고정 | task specific한 값 사용 |
실험 및 결과
문제의 상황에 따른 구조
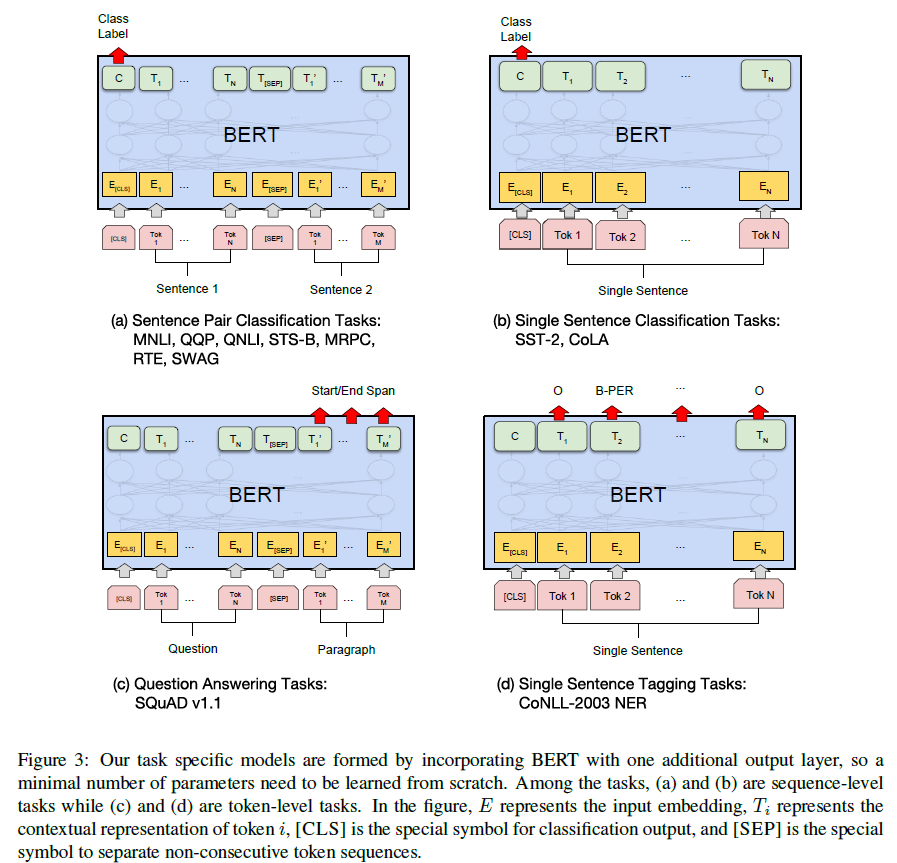
BERT가 짱이다
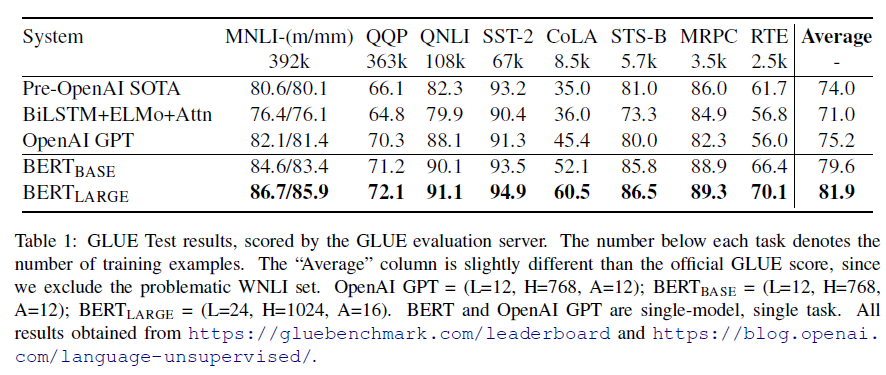
가능하게 한 원인 분석
Pre-training의 영향
- NO NSP: MLM 사용/ NSP를 지움
- LTR & NO NSP: MLM 대신 LTR(Left to Right) 사용 / NSP 지움
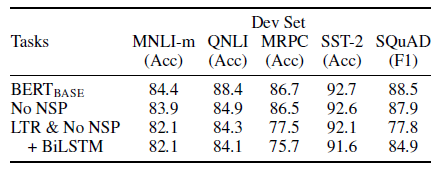
-> MLM과 NSP의 영향이 크다.
Model size의 영향
층의 개수, hidden unit의 수, attention head의 수를 바꿔가며 실험( 나머지는 기존과 동일)
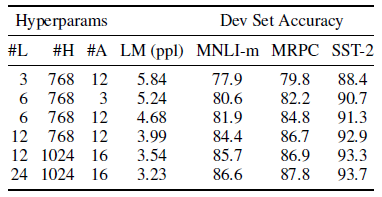
MRPC의 경우 3600개의 training example인데 BERT_BASE보다 BERT_LARGE에서 더 학습이 잘 된다.
-> pre-training이 잘 되어 있다면 학습 데이터가 작고 모델 사이즈가 커도 더 잘 찾아내는 것을 증명했다. (overfitting이 난다는 생각을 뒤집음)
training step 수의 영향
Q. fine-tuning 단계에서 높은 정확도를 얻으러면, pre-training 단계에서 많은 training 스텝이 필요한가??
-> A. 그렇다
Q. MLM으로 학습하면 15%의 단어만 맞추는 걸로 학습해도 LTR보다 converge하는 속도가 훨씬 느리지 않냐?
-> A. 조금 느리다. 근데 성능은 좋다.
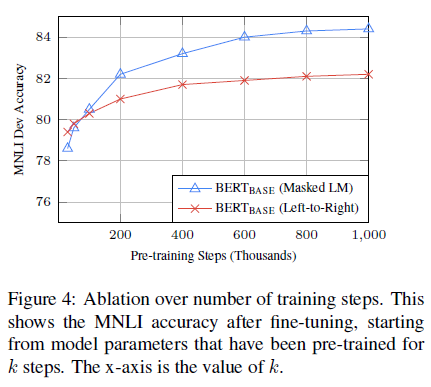
feature-based 방식의 BERT
fine-tuning이 아닌 feature-based 방식으로 접근해도 잘 된다.

참고자료
- https://mino-park7.github.io/nlp/2018/12/12/bert-논문정리/?fbclid=IwAR3S-8iLWEVG6FGUVxoYdwQyA-zG0GpOUzVEsFBd0ARFg4eFXqCyGLznu7w
- https://dnddnjs.github.io/nlp/2019/05/08/BERT/
- http://docs.likejazz.com/bert/
- https://arxiv.org/pdf/1810.04805.pdf