Attention 논문 정리
Attention Is All You Need
개요 & 배경
RNN(또는 CNN)은 입력으로 문장을 단어 순서대로 받는다.(t번째에 대한 output을 만들기 위해, t번째 input과 t-1번째 hidden state 사용)
순서대로 계산해야 하기 때문에 병렬 처리를 할 수 없어 계산 속도가 느리다는 단점이 있다. (Parallelization)
그리고, 문장이 너무 길다면 멀리 있는 단어의 정보를 잃어버리게 되는 단점이 있다. (Long-term dependency problem)
이러한 문제의 해결방안 중 하나는 Convolution seq2seq
- Convolution을 사용하면 병렬처리가 가능
- 계층적 Convolution 사용(CNN을 계속 쌓아 멀리 있는 단어에 대한 처리도 가능)
- Positional Embedding(입력 임베딩에 순서도 추가)
- Multi-step attention: attention이 decoder의 state와 이전 단어의 임베딩으로부터 학습됨

하지만 고정된 사이즈의 벡터로 표현하기 때문에 입력이 길다면 일부를 잃어버릴 수 있다.
그리고 학습할 때 시간이 오래 걸린다. O(n logn)
transformer는 순서대로 있는 것들을 2개의 input/output sequence로 하여 O(1)의 작업을 수행한다.
모델 구조
인코더가 입력 (x1 … xn) -> z = (z1 … zn)으로 매핑
디코더는 z -> (y1 … yn)으로 생성
각 스텝에서 모델은 auto-regressive(이전에 생성된 것을 다음 것을 생성할 때의 입력으로 사용)
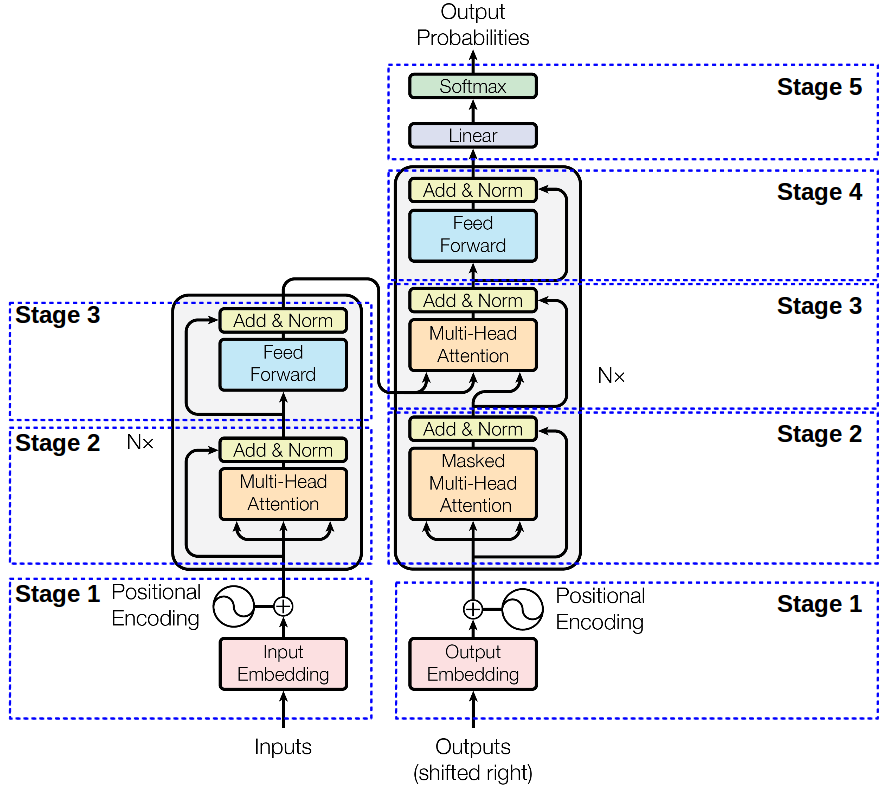
인코더 - 디코더 층
인코더와 디코더 모두 동일한 층의 뭉치로 구성되어 있다.
각 동일한 층은 2가지의 하위 층으로 구성되어 있다.
- multi-head self-attention mechanism
- position-wise fully connected FFN 인코더
- stage1
인코더의 입력은 positional encoding(순서에 대한 정보가 저장되어 있음) ⊕ embedding inputs
- stage2,3
N = 6 -> 인코더는 6개의 동일한 층으로 구성되어 있음
각각의 층은 두개의 하위 층(multi-head self-attention mechanism, position-wise fully connected FFN)으로 구성되어 있음
두 개의 하위 층은 layer normalization 과 residual connection이 적용되어 있다. LayerNorm(x + Sublayer(x))
그래서 출력의 차원을 맞춰줘야 한다.(d_model = 512)
디코더
- stage1
디코더의 입력은 positional encoding(순서에 대한 정보가 저장되어 있음) ⊕ 출력 임베딩
- stage2
masking을 통해, positon i보다 이후에 있는 position에 attention을 주지 못하게 함
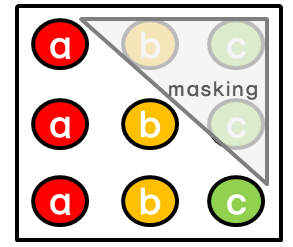
위의 그림에서 a를 예츧할 때 a 이후에 있는 b,c에는 attention이 주어지지 않음
- stage2,3,4
N = 6 -> 인코더는 6개의 동일한 층으로 구성되어 있음
각각의 층은 두개의 하위 층(multi-head self-attention mechanism, position-wise fully connected FFN)으로 구성되어 있음
두 개의 하위 층은 layer normalization 과 residual connection이 적용되어 있다. LayerNorm(x + Sublayer(x))
그래서 출력의 차원을 맞춰줘야 한다.(d_model = 512)
stage3에서 인코더와 달리 인코더의 결과게 multi-head attention을 수행할 sub-layer를 추가해야 한다.
Embeddings and Softmax
- stage5
임베딩 값을 고정시키지 않고, 학습을 하면서 임베딩 값이 변경되는 learned embedding 사용
디코더 출력을 다음 토큰의 확률로 바꾸기 위해 learned linear transformation과 softmax 사용
learned linear transformation을 사용한 것은 디코더의 출력에 weight matrix W를 곱하는데, 이 때 W가 학습된다는 것을 의미한다.
Attention
attention은 단어의 의미처럼 특정 정보에 좀 더 주의를 기울이는 것
모든 토큰이 비슷한 중요도를 갖기 보다는 특정 토큰에서 더 큰 중요도를 갖게 만드는 방법
Scaled Dot-Product Attention
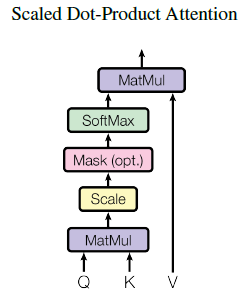
입력
- Q: query ( dk 차원) matrix
- K: keys ( dk 차원) matrix
- V: values (dv 차원) matrix
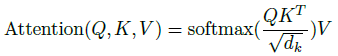
가장 많이 쓰이는 attention은 additive attention과 dot-product attention이 있다.
두 가지의 complexity는 이론적으로 유사하지만, dot-product attention이 더 빠르고, space-efficient하다.
dk가 작을 때는 additive attention이 더 좋지만, dk가 클 때는 dot-product attention이 더 좋다.
기존의 dot-product attention을 √dk로 나누는 이류는 dot-product의 값이 커질수록 softmax 함수에서 기울기의 변화가 거의 없는 부분으로 가기 때문
softmax를 거친 값을 value에 곱해준다면, query와 유사한 value일수록 더 높은 값을 가지게 됨 (attention)
###### Multi-head attention
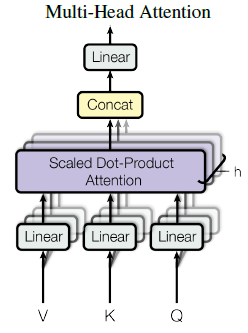

dmodel 차원의 key,value,query들로 하나의 attention을 수행하는 것 보다 key,value,query들에 각각 다른 학습된 linear project을 h번 수행
projection matrix: 각각의 값들이 parameter maritx와 곱해졌을 때 dk,dv,dmodel 차원으로 project하기 때문
project된 key,value,query들은 병렬적으로 attention을 거쳐 dv 출력
여러 개의 head를 concat하여 다시 projection 수행 -> 최종 dmodel 출력
Self-Attention
- 인코더에서 key, value, query 들은 모두 이전 layer의 output에서 온다. 그래서 이전 layer의 모든 position에 attention을 줄 수 있다.
- 디코더에서도 인코더와 비슷하게 self-attention을 줄 수 있다. 하지만, auto-regressive한 특성을 유지하기 위해 masking
- RNN,CNN 대신 self-attention을 사용한 이유
- 계산 복잡도 최소화(self-attention -> O(1) vs RNN -> O(n))
- 최소의 sequence operation을 이용하여 병렬 처리 증가(sequence가 n이고, representaion dimensionality가 d이면 n<d일 때 RNN보다 빠르다. 그리고 근처의 사이즈가 r이라면 O(n/r))
- 다른 타입의 층의 결합으로 2개의 입력 사이의 최대거리를 감소하여 Long-term dependency problem 해결
Position - wise FFN
인코더와 디코더의 각 층은 fully connected feed-forear network를 가진다.
position마다(개별 단어마다) 적용되기 때문에 position-wise
network는 두번의 linear transformation과 ReLU로 구성
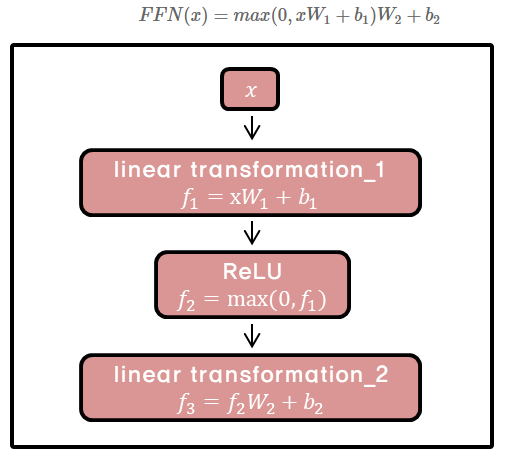
각각의 position마다 같은 파라미터 W,b를 사용하지만, layer가 달라지면 다른 파라미터 사용
kernel size가 1이고 channel이 layer인 convolution을 두 번 수행한 것과 유사
Positional Encoding
transformer는 recurrence도 아니고 convolution도 아니기 때문에, 단어의 sequence를 이용하기 위해서 position에 대한 정보를 추가해줄 필요가 있다.
그래서 input embedding에 positional encoding 추가
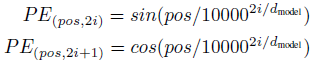
pos는 position, i는 dimension이고 주기가 10000 2i/dmodel * 2π인 삼각함수
k=2i+1일 때는 cosine 함수, k=2i일 때 sine 함수 이용
pos마다 다르게 구하기 때문에 같은 column이라고 할지라고 pos가 다르다면 다른 값을 가지게 됨
즉, pos마다 다른 pos와 구분되는 positional encoding 값을 얻게 된다.
이러한 성질 때문에 model이 relative position에 의해 attention하는 것을 더 쉽게 배울 수 있다.
학습

transformer 학습 과정
실험환경
- WMT 2014 English-german dataset (4.5m sentence pair)
- 문장들은 byte-pair encoding으로 인코딩됨 ( 37000 토큰)
- WMT 2014 English-French dataset(36M)
- 32000 word-piece
sentece pair는 거의 sequence 길이로 배치
NVIDIA P100 GPU 8개
- Base 모델
- 각 스텝에서 0.4초
- 100000스텝 -> 대략 12시간
- big 모델
- 각 스텝에서 1초
- 300000스텝 -> 3.5일
Optimizer
Adam 사용
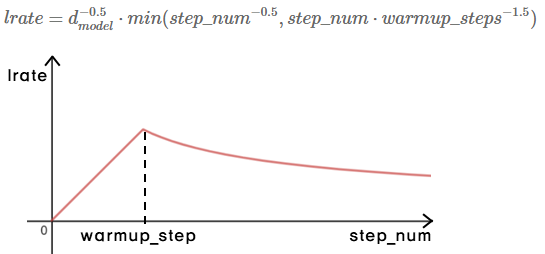
warmup_step까지 linear하게 learning rate를 증가시키다가 warmup_step 이후에는 감소
처음에는 학습이 잘 되지 않은 상태이므로 learning rate를 빠르게 증가시켜 변화를 크게 주다가. 학습이 꽤 됐을 시점에 laerning rate를 천천히 감소시켜 변화를 작게 준다.
warmup_steps = 4000 사용
Regularization
Residual Dropout
각 sub-layer의 출력에 dropout 적용
추가적으로, 임베딩과 positional encoding(인코더 디코더 모두)의 합에 dropout 적용
dropout = 0.1
Label Smoothing
training 동안 실제 정답인 label의 logit은 다른 logit보다 훨쓴 큰 값을 가지게 됨
하지만 overfitting이 생기거나 가장 큰 logit을 가지는 것과 나머지 사이의 차이를 점점 크게 만들어버린다.
결국 model이 다른 data에 적응하는 능력을 감소시킴
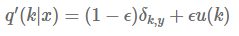
u(k)는 label에 대한 분포/ δk,y는 k가 y일 경우 1, 나머지는 0 / ϵ는 smoothing parameter
| 그래서 k=y인 경우에도 model은 p(y | x) = 1이 아니라 1- ϵ |
ϵ = 0.1
## 결론
recurrence를 이용하지 않고도 빠르고 정확하게 sequential data 처리
encoder와 decoder에서 attention을 통해 query와 가장 밀접한 연관성을 가지는 value 강조
병렬화 가능
참고자료
- https://mchromiak.github.io/articles/2017/Sep/12/Transformer-Attention-is-all-you-need/#.XO5AlIgzaUl
- https://pozalabs.github.io/transformer/
- https://arxiv.org/abs/1706.03762